
近年、AI技術の進化により、自分や他人の声を再現できる「ボイスクローン」が注目を集めています。
プロの現場だけでなく、日常的な用途でも活用が広がり、初心者でも手軽に使えるようになっています。
本記事では、無料でボイスクローンを試したい方に向けて、その方法をわかりやすく紹介します。
無料でボイスクローンを行う2つの方法
ボイスクローンは、工夫次第で無料でも実現できます。主な方法は大きく分けて以下の2つです。
1. 無料のオープンソースを利用する
無料で公開されているオープンソースのボイスクローンツールを使う方法です。
✅ メリット
- 完全無料で利用できる
- 回数制限がなく、自由に試せる
✅ デメリット
- 環境構築や設定が必要な場合が多い
- パソコンのスペックに一定の要件がある
- 操作がやや複雑で、初心者にはハードルが高い
2. 有料サービスの無料プランを活用する
有料のボイスクローンサービスが提供している無料プランを利用する方法です。
✅ メリット
- ブラウザ上で手軽に利用できる
- 操作がシンプルで初心者でも使いやすい
✅ デメリット
- 無料プランでは利用回数や機能に制限がある
- 出力音声に制限(ロゴや品質制限など)が付く場合がある
無料で試せるボイスクローンサービス3選
ここでは、高性能かつ高精度で、無料で手軽に試せるボイスクローンサービスを3つ紹介します。
※音声クローンといえば、ElevenLabs(イレブンラボ)はプロ品質でトップクラスのサービスといえるでしょう。ただし、音声クローン機能は有料プラン限定です。
1. Fish Audio
- おすすめポイント:自然で高品質な音声生成/ゆとりある無料利用枠の設定
- 注意点:短文や強い演出ではElevenLabsに劣る場合がある
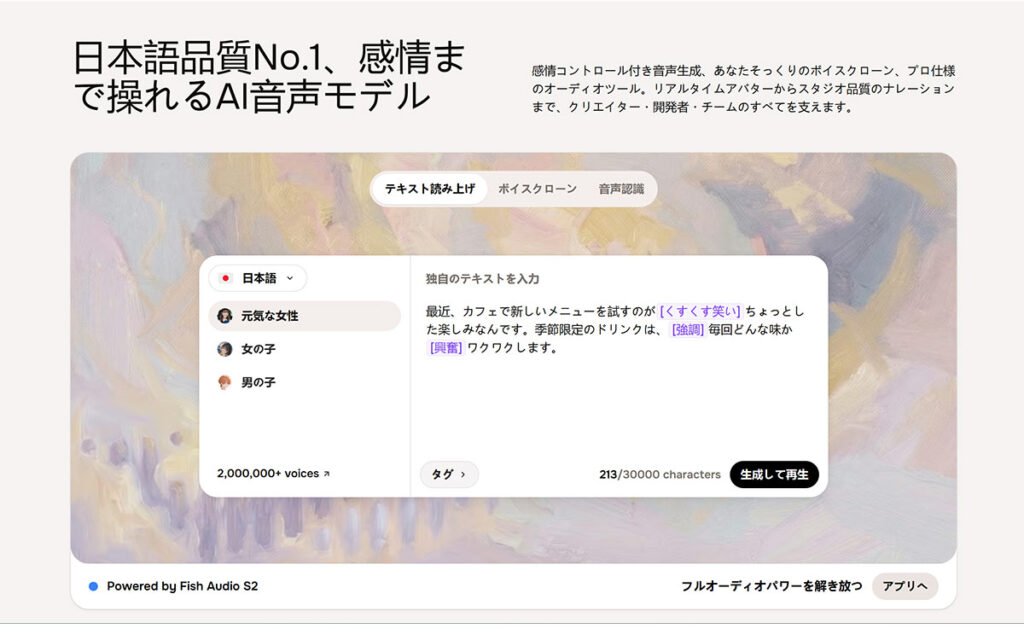
Fish Audioは、AI音声技術に特化した次世代の音声合成プラットフォームです。
感情コントロール付きの音声生成や高精度なボイスクローン、プロ向けツールを備え、リアルタイム用途から高品質なナレーション制作まで幅広く対応しています。
ElevenLabsとよく比較され、仮にElevenLabsがトップだとすれば、Fish Audioは2〜3番手に位置し、性能はおよそ8割程度と評価されています。
ナレーションでは両者の差は小さく、特に長めの音声では違いを感じにくい一方、短いフレーズや表現力ではElevenLabsがやや優れています。
また、Fish Audioはコミュニティによる豊富な音声ライブラリを備えており、サンプル音声を用意せずに多様な声を手軽に試せる点も魅力です。
実用面では自然な音声を生成できるうえ、価格も比較的手頃なため、コストパフォーマンスに優れた選択肢といえます。
| Fish Audio | |
| 対応OS | ブラウザ |
| どの国 | アメリカ |
| 対応言語 | 英語、日本語、韓国語、中国語、フランス語、 ドイツ語、アラビア語、スペイン語など |
| 無料枠 | ①クローン音声は非公開に設定不可 ②アカウント登録で、8,000クレジットが無料で付与 ※文字数に応じて消費され、クローン音声をダウンロード可能。 |
| 有料プラン | 文字単位でのイントネーション調整が可能 |
| 商用利用 | 有料プランでのみ可能 |
| 公式サイト | https://fish.audio/ja/ |
2. Speechify
- おすすめポイント:極短時間での高速学習/自然で生身に近い高品位音声
- 注意点:利用規模に応じた高額なコスト/オフライン環境での機能制限
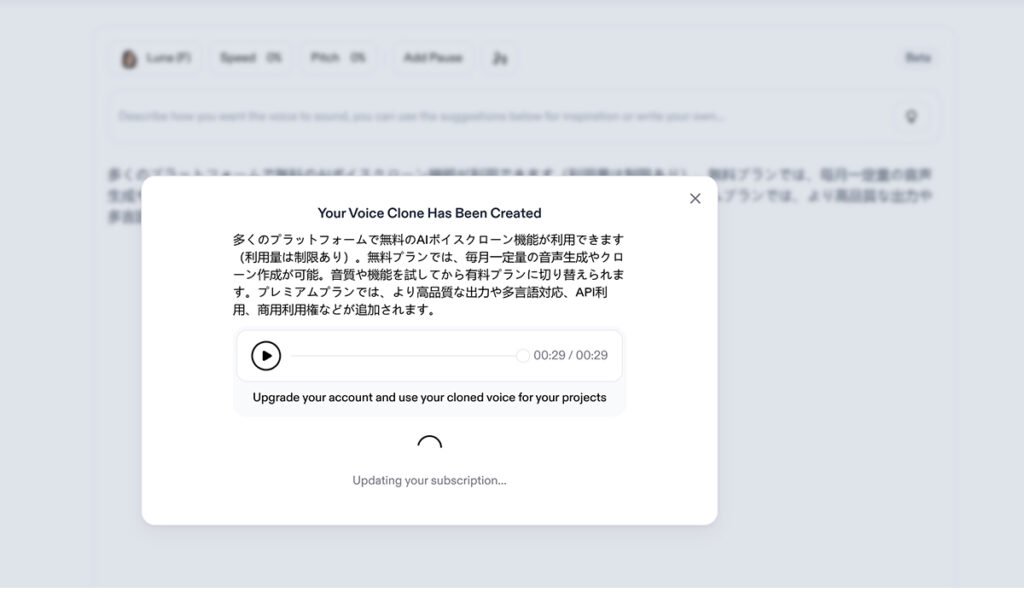
Speechifyは、クリフ・ワイツマン氏が自身の読字障害(ディスレクシア)を克服するために開発したAI音声読み上げサービスです。
AIボイス生成機能を使えば、自分の声をクローンし、さまざまなプロジェクトで高品質な合成音声を作成できます。オーディオブックやコンテンツ制作などにおいて、まるで本人のような自然な音声を再現できるのが特徴です。
ブラウザ版ではアカウント登録不要で、すぐに無料体験が可能です。音声クローンは、音声サンプルのアップロードに加え、その場で録音して作成することもできます。
学習速度も非常に速く、デフォルトで英語のクローン音声をプレビュー可能です。また、日本語などのテキストを入力して読み上げることもでき、最大1000文字まで無料対応しています。
実際に試したところ、日本語・英語ともに元の声の特徴をしっかり捉えており、違和感の少ない自然な仕上がりでした。
| Speechify | |
| 対応OS | Windows・Mac・iOS・Android・ブラウザ |
| どの国 | アメリカ |
| 対応言語 | 英語、日本語など多言語対応 |
| 無料枠 | クローン音声は、英語で最大38秒までプレビューできる |
| 有料プラン | $19/月から |
| 商用利用 | 有料プランでのみ可能 |
| 公式サイト | https://speechify.com/ja/voice-cloning/ |
3. LALAL.AI
- おすすめポイント:日英対応の歌唱・対話音声プレビュー/直感的で使いやすい操作性
- 注意点:言語による自然さの格差(英語優位)/出力音量の不安定さ
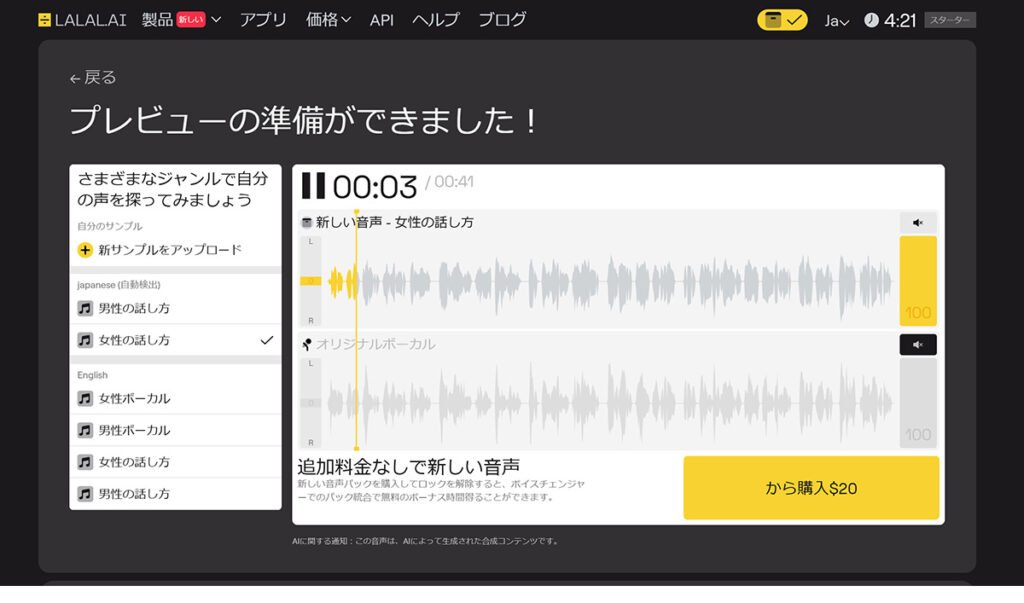
LALAL.AIとは、音声や楽曲からボーカルや特定の音を高精度で分離できるAIサービスです。
中には、「音声クローン」という機能を搭載して、自分や他人の声をAIで再現することができます。
音声クローンの作成には、10〜50分程度のクリアな音声サンプルをアップロードしてトレーニングを行います。
プレビューでは、音声の言語が自動検出され(本ケースでは日本語)、検出された言語と英語のそれぞれで、話し声やボーカルの再現結果を確認できます。仕上がりに満足できない場合は、音声サンプルを追加して精度を向上させることも可能です。
検証では、日本語のサンプルを使用した場合でも、英語の話し声のほうが自然に感じられましたが、音量にばらつきが見られる点には注意が必要です。
問題がなければ、そのままボイスチェンジャー機能に統合して利用できます。
| LALAL.AI | |
| 対応OS | Windows・Mac・iOS・Android・ブラウザ |
| どの国 | スイス |
| 対応言語 | 英語、日本語など多言語対応 |
| 無料枠 | 音声ファイルの出力は有料プラン限定 |
| 有料プラン | ¥2500 / 回 / 1音声パック(20分間内) |
| 商用利用 | 有料プランでのみ可能 |
| 公式サイト | https://www.lalal.ai/ja/voice-cloning/ |
無料で使えるオープンソースのボイスクローンツール4選
無料で使えるオープンソースのボイスクローンツールは、自由度が高くコストを抑えられるのが特徴です。
ここでは、おすすめのツールを厳選して紹介します。
1. Qwen3-TTS
- おすすめポイント:3秒の即時クローン/低遅延・リアルタイム/最新の高性能モデル
- 注意点:早口の傾向/細かな調整が難しい
Qwen3-TTSは、Alibaba(アリババ)が2026年1月22日にオープンソースとして公開した最新の音声合成AIです。
97ms低遅延でリアルタイム音声生成が可能な点が大きな特徴で、流式・非流式の両方に対応しながら、入力に応じて即座に音声を生成できます。
また、大量の音声データで学習されているため、抑揚や間、呼吸感まで再現した自然で人間らしい高品質な音声を出力でき、リアルタイム対話からプロ用途まで幅広く活用できます。
ボイスクローン機能では、高品質には10〜20秒(最長60秒)のクリアな音声が推奨され、専用スペースやAPIも提供されています。Hugging Face上には公式デモもあり、ブラウザから手軽に試せます。
実際に使用すると、クローンの手軽さは優れている一方で、読み上げ速度がやや速く感じられる場合があります。また、現時点ではピッチやイントネーションの細かな制御には対応していない点に注意が必要です。
| Qwen3-TTS | |
| 提供元 | Alibaba(中国) |
| 対応言語 | 英語、日本語など多言語対応 |
| ライセンス | Apache 2.0 |
| 商用利用 | 可能(制限あり) |
| 詳細ページ | https://github.com/QwenLM/Qwen3-TTS |
2. Chatterbox
- おすすめポイント:豊かな声の再現性/文脈に応じた抑揚/多言語対応&低遅延
- 注意点:発音・アクセントの不整合/長文での精度低下/非言語音(笑い声やため息)の非対応
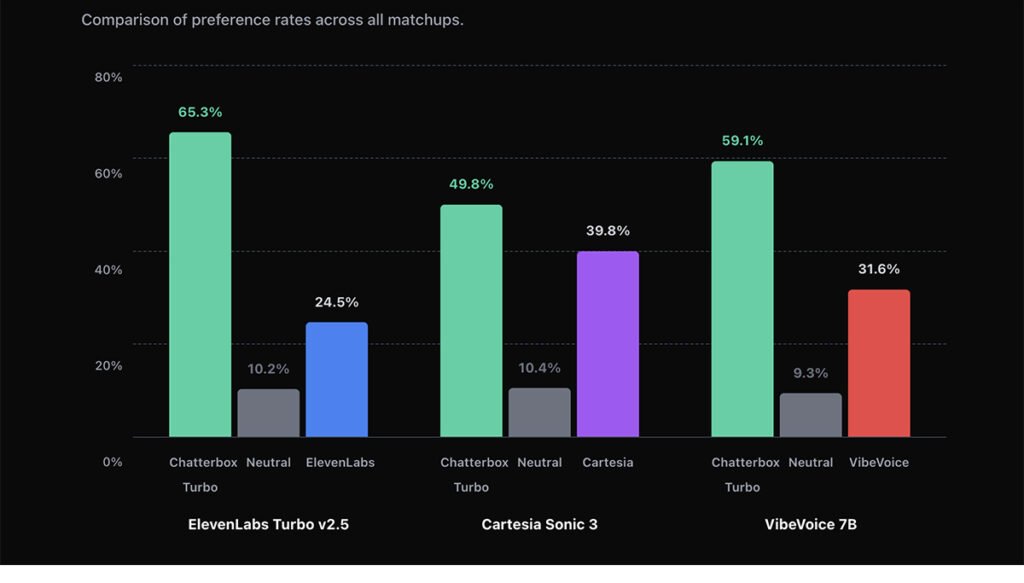
Chatterboxとは、Resemble AIが開発したオープンソースのテキスト読み上げ(TTS)モデル群です。
約5億パラメータの大規模アーキテクチャと50万時間の音声データで学習されており、高品質な音声生成を実現しています。
用途に応じて「通常版」「多言語版」「Turbo版」の3種類があり、通常版は音質と感情表現に優れ、多言語版は23言語以上に対応、Turbo版は200ms未満の低遅延でリアルタイム用途に適しています。
また、感情の強弱や話し方のニュアンスを細かく調整できるほか、少量の音声から声を再現するボイスクローン機能も備えており、ナレーションやAIキャラクター生成など幅広い用途に活用可能です。
一方で、設定次第では高品質な音声を生成できる反面、アクセントが不安定になる場合もあります。
さらに、ElevenLabsの対抗馬として評価される一方、長時間音声では自然さや感情表現の一貫性に差が見られるとされています。
| Chatterbox | |
| 提供元 | Resemble AI(アメリカ) |
| 対応言語 | 多言語対応(※Turbo版は英語のみ対応) |
| ライセンス | Apache 2.0 |
| 商用利用 | 可能(制限あり) |
| 詳細ページ | https://www.resemble.ai/chatterbox/ |
3. VibeVoice
- おすすめポイント:圧倒的な声の再現性/キャラボイスや特殊な声質も忠実に再現
- 注意点:音質にムラがあるため、クオリティ向上には高いマシンスペックを推奨
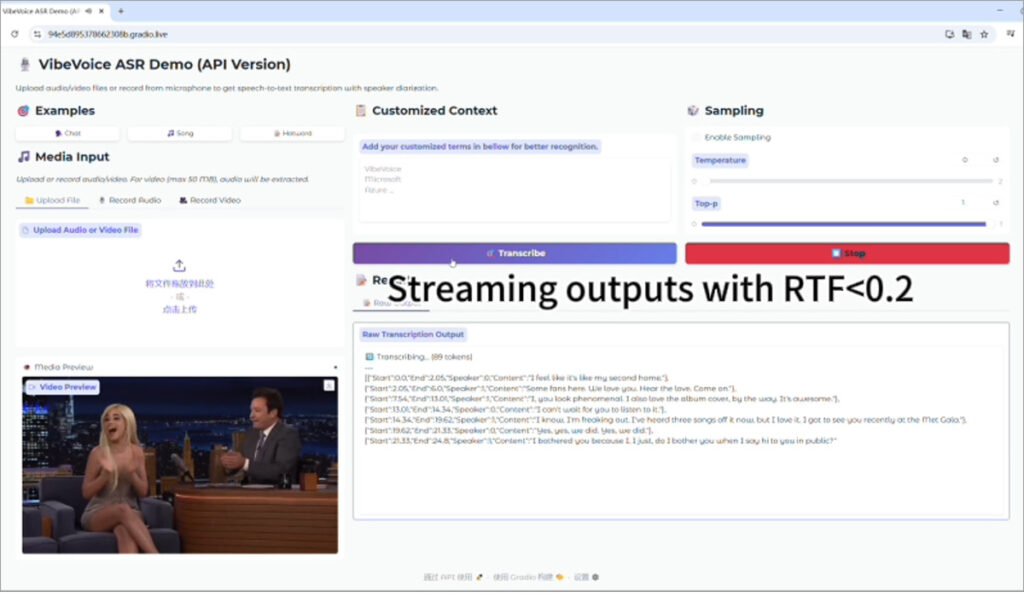
VibeVoiceとは、Microsoftが開発したオープンソースの次世代音声合成(TTS)フレームワークです。
既存のオープンソースモデルの中でも、「元の声にどれだけ近づけるか」という点でトップクラスの性能を持ち、音調やアクセントの再現力に優れています。
特に、ゲームキャラクターや政治人物、映画の登場人物など、一般的なTTSでは再現が難しい声でも高精度に模倣できます。
一方で、音質は必ずしも最高レベルではなく、ノイズや不自然さが残る場合があります。これは技術的制約によるもので、さらなる高品質化にはモデルの進化や計算リソースの強化が必要とされています。
それでも「声の再現性」においては非常に優秀で、用途によってはElevenLabsの代替としても実用的です。
総じてVibeVoiceは、音質よりも再現性を重視する用途に適したTTSといえます。
| VibeVoice | |
| 提供元 | Microsoft(アメリカ) |
| 対応言語 | 英語、中国語、日本語など |
| ライセンス | MIT |
| 商用利用 | 可能 |
| 詳細ページ | https://github.com/microsoft/VibeVoice |
4. MOSS-TTS
- おすすめポイント:自然で高品質な音声生成/ゆとりある無料利用枠の設定
- 注意点:短文や強い演出ではElevenLabsに劣る場合がある

MOSS-TTSとは、上海创智学院OpenMOSSチームと模思智能が開発したオープンソースの音声生成モデル群です。
16億パラメータと300万時間のデータで学習されており、短い音声から30分規模の長時間音声まで、安定して高い品質を維持できる設計になっています。
高音質と高い表現力を両立し、ナレーションから対話、リアルタイム音声まで幅広く対応できるのが特徴です。
音声クローンや感情表現、複数人の会話生成に対応するほか、環境音や効果音も生成可能で、音声と音響を一体的に扱えます。
簡単なテストの結果、生成音声は自然で、Qwen TTSのような感情の乏しさは感じられませんでした。音質はVibeVoice Largeにやや及ばないものの、安定性に優れ、IPA対応により実用性も高いといえます。
処理速度も良好で、R9700プロセッサ搭載・GPU使用率約80%・VRAM 26GBの環境において、約1分20秒の音声生成におよそ55秒を要しました。
| MOSS-TTS | |
| 提供元 | OpenMOSS(中国) |
| 対応言語 | 英語、中国語、日本語、韓国語、スペイン語、 フランス語、ドイツ語など |
| ライセンス | Apache License 2.0 |
| 商用利用 | 可能(制限あり) |
| 詳細ページ | https://github.com/OpenMOSS/MOSS-TTS |
まとめ
以上、無料でボイスクローンを行う方法として、「オープンソース」と「有料サービスの無料プラン」の2つを紹介しました。
手軽に試すなら、Fish AudioやSpeechify、LALAL.AIなどのサービスがおすすめです。
一方、自由度を重視するなら、Qwen3-TTSやChatterbox、VibeVoice、MOSS-TTSといったオープンソースが適しています。
現時点では、依然としてElevenLabsなどの商用サービスが先行していますが、その差は急速に縮まっています。オープンソースには長尺生成時の安定性や一貫性に課題を残すものの、進化のスピードは驚異的です。
まずは目的に合わせ、これらのツールを無料で体験し、その可能性を確かめてみてください。
